SQL Server Optimisation: Why Less Is More
One of the most valuable lessons I’ve learned in performance tuning is the importance of breaking queries tasks into smaller, more manageable sections. Who knew? The experts were right all along when they said, “If you’re confused by the query, SQL probably is too”.
In today’s post, we will cover a simple, but powerful concept when trying to write queries.
A common sight as a DBA is long, monolithic queries attempting to do ALL THE THINGS in one pass (including solving world peace, all powered by a table variable).
Joking aside, the longer and more complex a query is, the greater the chance of issues arising, especially as the database grows over time. That 10,000 line stored procedure may run fine in the early days when you have 100 records in each table. However, it won’t last.
Predicting The Future
One thing that happens when you execute a query in SQL Server is that SQL quickly determines the optimal execution plan for your query. At this point, things can go wrong with large, complex queries. SQL must estimate multiple factors, including how many records pass through the query at different stages of dataset processing. The more datasets being rendered, the more logic there is, the more complex the joins; the more pushed SQL is going to be for making good judgement calls within that tiny window of time.
Divide And Conquer
Fear not, intrepid reader - we can assist SQL in making smarter decisions. There is a concept which can help us here called ‘materialising’ datasets. We can take an approach that guides SQL as it rapidly makes judgement calls about retrieving the tables and columns you’ve joined. Minimising the number of rows we need to work with as quickly as possible, as early as possible, can have significant effects on your query’s performance.
Demo: Setting The Stage
Lets do a demo to show what I mean. I will be using:
- SQL Server 2022
- StackOverflow2013 database, in compatibility level 160
Here we have an ugly query, it’s joining up dataset to dataset, adding various conditional logic along the way too. Reading this type of query hurts, but I am trying to make a point here, and it’s not ’that’ different to what I will commonly see out in the wild. You don’t need to understand it all - you don’t even need to read it all. I just want you to be mindful of the number of joins, hops, spins arounds and touch the grounds we are doing throughout it.
USE StackOverflow2013;
GO
DROP TABLE IF EXISTS #GetQuestionAndAnswers;
DROP TABLE IF EXISTS #GetQuestionAndAnswers2;
;WITH GetQuestions AS
(
SELECT
'Question' AS Q,
p.Title,
p.OwnerUserId
FROM dbo.Posts p
WHERE p.PostTypeId = 1
AND EXISTS (SELECT 1 FROM dbo.Users u WHERE p.OwnerUserId = u.Id AND u.WebsiteUrl <> '')
),
GetAnswers AS
(
SELECT
'Answer' AS A,
p.Title,
p.OwnerUserId
FROM dbo.Posts p
WHERE p.PostTypeId = 2
AND EXISTS (SELECT 1 FROM dbo.Users u WHERE p.OwnerUserId = u.Id AND u.WebsiteUrl <> '')
),
GetQuestionAndAnswers AS
(
SELECT
GetQuestions.Q,
GetQuestions.Title,
GetQuestions.OwnerUserId
FROM GetQuestions
UNION ALL
SELECT
GetAnswers.A,
GetAnswers.Title,
GetAnswers.OwnerUserId
FROM GetAnswers
)
SELECT
SUM(CASE WHEN qa.Q = 'Question' THEN 1 ELSE 0 END) AS TotalQuestions,
SUM(CASE WHEN qa.Q = 'Answer' THEN 1 ELSE 0 END) AS TotalAnswers
INTO #GetQuestionAndAnswers
FROM GetQuestionAndAnswers qa
;WITH GetQuestions2 AS
(
SELECT
'Question' AS Q,
p.Title,
p.OwnerUserId
FROM dbo.Posts p
WHERE p.PostTypeId = 1
AND EXISTS (SELECT 1 FROM dbo.Users u WHERE p.OwnerUserId = u.Id AND u.WebsiteUrl = '')
),
GetAnswers2 AS
(
SELECT
'Answer' AS A,
p.Title,
p.OwnerUserId
FROM dbo.Posts p
WHERE p.PostTypeId = 2
AND EXISTS (SELECT 1 FROM dbo.Users u WHERE p.OwnerUserId = u.Id AND u.WebsiteUrl = '')
),
GetQuestionAndAnswers2 AS
(
SELECT
GetQuestions2.Q,
GetQuestions2.Title,
GetQuestions2.OwnerUserId
FROM GetQuestions2
UNION ALL
SELECT
GetAnswers2.A,
GetAnswers2.Title,
GetAnswers2.OwnerUserId
FROM GetAnswers2
)
SELECT
SUM(CASE WHEN qa.Q = 'Question' THEN 1 ELSE 0 END) AS TotalQuestions,
SUM(CASE WHEN qa.Q = 'Answer' THEN 1 ELSE 0 END) AS TotalAnswers
INTO #GetQuestionAndAnswers2
FROM GetQuestionAndAnswers2 qa
;WITH AllTogether AS
(
SELECT 'Users With Website' AS [Category], * FROM #GetQuestionAndAnswers
UNION ALL
SELECT 'Users Without Website' AS [Category], * FROM #GetQuestionAndAnswers2
)
SELECT
MAX(CASE WHEN Category = 'Users With Website' THEN TotalQuestions END) AS TotalQuestionsWithURL,
MAX(CASE WHEN Category = 'Users With Website' THEN TotalAnswers END) AS TotalAnswersWithURL,
MAX(CASE WHEN Category = 'Users Without Website' THEN TotalQuestions END) AS TotalQuestionWithoutURL,
MAX(CASE WHEN Category = 'Users Without Website' THEN TotalAnswers END) AS TotalAnswersWithoutURL
FROM AllTogether a;
Demo: We Can Do Better
As you have seen, we have a long messy query which utilises all the things along the way.
When tackling a query like this, I try to apply the following strategies:
- Identify logical breaking points within the dataset rendering process: Think about how I can spoon-feed SQL information (food?) along the way. Can we try and ‘materialise’ any datasets early in the logical processing of the query? My primary goal here is to shore up the estimates as early as possible. Better estimates mean better-resourced queries, which means better performance.
- Look for repeated work or the repeated accessing of objects: The old adage is correct: the fastest query is the one you don’t run. Too often I will see queries hitting the same table, several times in different ways when just one pass of the object would have done.
Within the mess that is our demo query above, there are two aspects which I would like to address:
1 Accessing the dbo.Users table - many times
We are repeatedly accessing the dbo.Users table to check that if corresponding post has a user with or without a website:
-- Example 1
AND EXISTS (SELECT 1 FROM dbo.Users u WHERE p.OwnerUserId = u.Id AND u.WebsiteUrl = '')
-- Example 2
AND EXISTS (SELECT 1 FROM dbo.Users u WHERE p.OwnerUserId = u.Id AND u.WebsiteUrl <> '')
Sure, I have amplified this aspect of the query somewhat for demonstration purposes. But it’s not that dissimilar to the things I will often see out in the wild. I understand how it can easily happen too. You have time-pushed, stressed developers, tacking on things over time and you end up with unnecessary work being done.
So how do we correct this issue? We ‘materialise’ a dataset early on within the query. Instead of querying the dbo.Users table four times, all we need to do is this, once:
INSERT INTO #UserDetail
SELECT
u.Id,
CASE WHEN u.WebsiteUrl <> '' THEN 1 ELSE 0 END AS WebExists,
CASE WHEN u.WebsiteUrl = '' THEN 1 ELSE 0 END AS WebDoesNotExist
FROM dbo.Users u;
We are materialising the dataset into a Temporary Table. This is a simple but important concept because:
- We only need to access the dbo.Users table once. One pass through it, and we have everything we need for the rest of the query
- Materialising the dataset into a temporary table instead of using a Common Table Expression (CTE), for example, is key. This gives us a dataset which is ‘static’ and does not need to be rendered each time it’s called. Statistics are also used with temporary objects which will further aid SQL to make better judgement calls when allocating resource, as it should have a decent idea of how many records the temporary table holds.
- We could even index the temporary table, should we need to.
2 Rendering the dbo.Posts data - all the ways, all the time
In a similar vein to the issue with the Users table, we are rendering information from the dbo.Posts table. We have multiple CTEs rendering Posts information, based on whether it’s a question or answer. Further down, we reassemble this collected information using a UNION to bring the multiple datasets back together.
Issue 1 : Repeated dataset renders for questions and answers
-- Example 1
WITH GetQuestions AS
(
SELECT
'Question' AS Q,
p.Title,
p.OwnerUserId
FROM dbo.Posts p
WHERE p.PostTypeId = 1
AND EXISTS (SELECT 1 FROM dbo.Users u WHERE p.OwnerUserId = u.Id AND u.WebsiteUrl <> '')
)
-- Example 2
GetAnswers AS
(
SELECT
'Answer' AS A,
p.Title,
p.OwnerUserId
FROM dbo.Posts p
WHERE p.PostTypeId = 2
AND EXISTS (SELECT 1 FROM dbo.Users u WHERE p.OwnerUserId = u.Id AND u.WebsiteUrl <> '')
)
Issue 2 : Unnecessary dataset combining
SELECT
GetQuestions.Q,
GetQuestions.Title,
GetQuestions.OwnerUserId
FROM GetQuestions
UNION ALL
SELECT
GetAnswers.A,
GetAnswers.Title,
GetAnswers.OwnerUserId
FROM GetAnswers
Once again, I have been a scamp here and have overdone it slightly to prove a point. However, it’s really not uncommon to see this type of process in the real world. I have often stared at my screen, reviewing somebody’s code, thinking “But…why?” (More worryingly, sometimes I realise it’s my own code)
Despite having those six CTEs (each rendering information from the dbo.Posts table) all we ultimately need to get the same output is the following:
SELECT
SUM(CASE WHEN p.PostTypeId = 1 AND u.WebExists = 1
THEN 1 ELSE 0 END) AS TotalQuestionsWithURL,
SUM(CASE WHEN p.PostTypeId = 2 AND u.WebExists = 1
THEN 1 ELSE 0 END) AS TotalAnswersWithURL,
SUM(CASE WHEN p.PostTypeId = 1 AND u.WebDoesNotExist = 1
THEN 1 ELSE 0 END) AS TotalQuestionWithoutURL,
SUM(CASE WHEN p.PostTypeId = 2 AND u.WebDoesNotExist = 1
THEN 1 ELSE 0 END) AS TotalAnswersWithoutURL
FROM dbo.Posts p
INNER JOIN #UserDetail u ON p.OwnerUserId = u.UserId
Key points about the above:
- We are able to make one pass of the dbo.Posts table
- Using logic (the CASE statements), we can simply get the status of the Post (question or answer) and SUM it accordingly
- We have finally joined against the temporary table #UserDetail
By rewriting the original query, we have reduced it from ~106 lines of code to just ~30. This is the final improved query:
USE StackOverflow2013;
GO
DROP TABLE IF EXISTS #UserDetail;
CREATE TABLE #UserDetail
(
UserId INT,
WebExists BIT,
WebDoesNotExist BIT
)
INSERT INTO #UserDetail
SELECT
u.Id,
CASE WHEN u.WebsiteUrl <> '' THEN 1 ELSE 0 END AS WebExists,
CASE WHEN u.WebsiteUrl = '' THEN 1 ELSE 0 END AS WebDoesNotExist
FROM dbo.Users u;
SELECT
SUM(CASE WHEN p.PostTypeId = 1 AND u.WebExists = 1
THEN 1 ELSE 0 END) AS TotalQuestionsWithURL,
SUM(CASE WHEN p.PostTypeId = 2 AND u.WebExists = 1
THEN 1 ELSE 0 END) AS TotalAnswersWithURL,
SUM(CASE WHEN p.PostTypeId = 1 AND u.WebDoesNotExist = 1
THEN 1 ELSE 0 END) AS TotalQuestionWithoutURL,
SUM(CASE WHEN p.PostTypeId = 2 AND u.WebDoesNotExist = 1
THEN 1 ELSE 0 END) AS TotalAnswersWithoutURL
FROM dbo.Posts p
INNER JOIN #UserDetail u ON p.OwnerUserId = u.UserId
Sure, you will just have to take my word for it here (or do the demo yourself), but just for completeness, here are the outputs of query 1 and 2:
Query 1 Output -

Query 2 Output -

Does It Run Better?
After all that effort, imagine if it performed exactly the same or, even worse, slowed down instead. 😄 Fortunately, it does run better, significantly so, in fact.
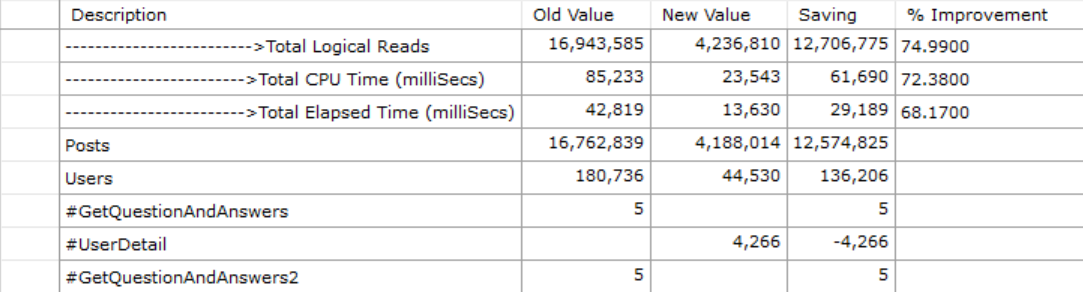
Using the output from STATISTICS IO and TIME, we have the following:
- Logical reads are down by 74%
- Total CPU time spent is down by 72%
- Total elapsed time is down by 68%
Drop it like its hawt
Thanks for reading!
If you’ve found this post helpful or would just like to support the work I do here, consider buying me a coffee.
