Parameter Sniffing: Practical Fixes That Work
Previously
In the previous post, we covered the basics of parameter sniffing with a simple demo to show what actually happens. We took a basic stored procedure and illustrated how the first plan to get cached can have severe performance implications.
Parameter sensitivity is a complex topic with many subtle nuances. It would be impossible to cover them all in a single blog post - although Erland Sommarskog gives it a good go in his mammoth blog post here.
In today’s post, Im going to discuss some of the options we have in our toolbox when faced with Parameter Sniffing issues. As with all things in SQL Server, each option comes with its own pros and cons, so they should always be used with caution and thoroughly tested.
This isn’t an exhaustive list, however its the ones I most commonly see used out in the wild.
Option Recompile
The query hint OPTION (RECOMPILE) instructs SQL Server to generate a new plan, each time the procedure executes. More precisely, it tells SQL Server to consider the current parameter values (rather than relying on cached estimates) when compiling the plan. In essence, adding a recompile hint forces SQL Server to craft a fresh execution plan on every execution.
However, this comes at a cost, and that cost is additional CPU usage. Additional CPU cost will be incurred each time this process happens, as SQL will not simply re-use a plan that happens to be in cache anymore. It will have to generate a new plan, and so, this costs.
With that in mind, I wouldn’t recommend adding this query hint to a procedure that runs 1,000 times per minute, for example.
However, if it’s a stored procedure that runs just a handful of times per minute? Sure, it’s a good solution to use in the right circumstance and has helped me out numerous times.
Two ways of implementing this query hint are either at the procedure level or statement level:
At procedure level
CREATE OR ALTER PROCEDURE dbo.Rincewind
@Badge AS NVARCHAR(40)
WITH RECOMPILE
AS
BEGIN
SELECT
b.Name AS [BadgeName],
b.UserId AS [UserId],
b.Date AS [DateAwarded]
FROM dbo.Badges b
WHERE b.Name = @Badge
END
GO
At statement level
CREATE OR ALTER PROCEDURE dbo.Rincewind
@Badge AS NVARCHAR(40)
AS
BEGIN
SELECT
b.Name AS [BadgeName],
b.UserId AS [UserId],
b.Date AS [DateAwarded]
FROM dbo.Badges b
WHERE b.Name = @Badge OPTION (RECOMPILE)
END
GO
Personally, I prefer adding the query hint at the statement level. This ensures that key metrics are still stored regarding the procedure.
For example - adding it at the procedure level will mean that key metrics about the procedure, such as ’number of executions’, will no longer be recorded or present for the procedure. For this reason, I always prefer adding it at the statement level. This ensures all the metrics are still recorded and retained (you never know when you might need them).
Option Optimize for Unknown
Another choice we could make is to use the OPTIMIZE FOR UNKNOWN query hint.
Example usage:
CREATE OR ALTER PROCEDURE dbo.Rincewind
@Badge AS NVARCHAR(40)
AS
BEGIN
SELECT
b.Name AS [BadgeName],
b.UserId AS [UserId],
b.Date AS [DateAwarded]
FROM dbo.Badges b
WHERE b.Name = @Badge OPTION (OPTIMIZE FOR UNKNOWN)
END
GO
This option is an interesting one because it will ultimately change how (or specifically what) SQL uses to predict the number of records it will encounter when executing the query. This query hint tells SQL to optimise for the average value passed via the parameter. To understand this concept, we’re going to have to look at statistics for a second.
Normally, when we execute a parameterised query (i.e. stored procedure), SQL Server will utilise what is called the histogram for the relevant statistic:
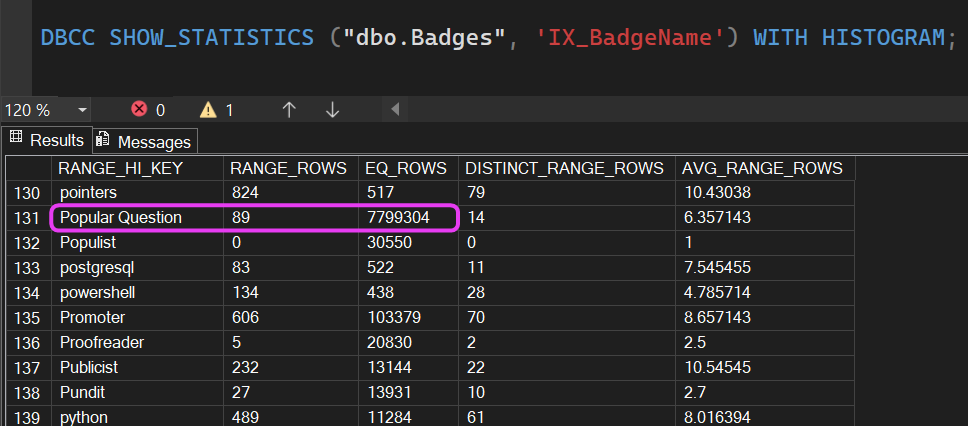
As shown above, via the statistics held, SQL knows that for the value ‘Popular Question’ - 7,799,304 records exist.
However, when we use OPTIMIZE FOR UNKNOWN, SQL no longer uses the histogram metric; it will use the density vector.

Now, to predict the number of records coming back, SQL will take the number of rows in the table and multiply that by the density vector value:
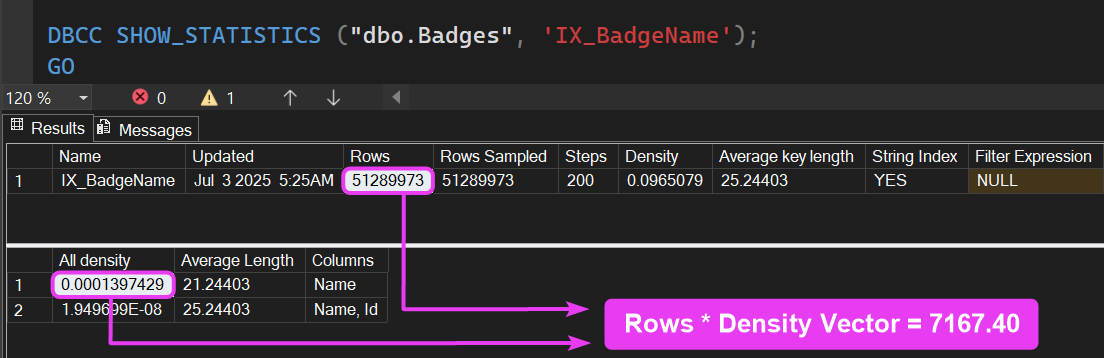
So, when SQL executes that query, it’s always going to predict 7,167 records are going to be read:
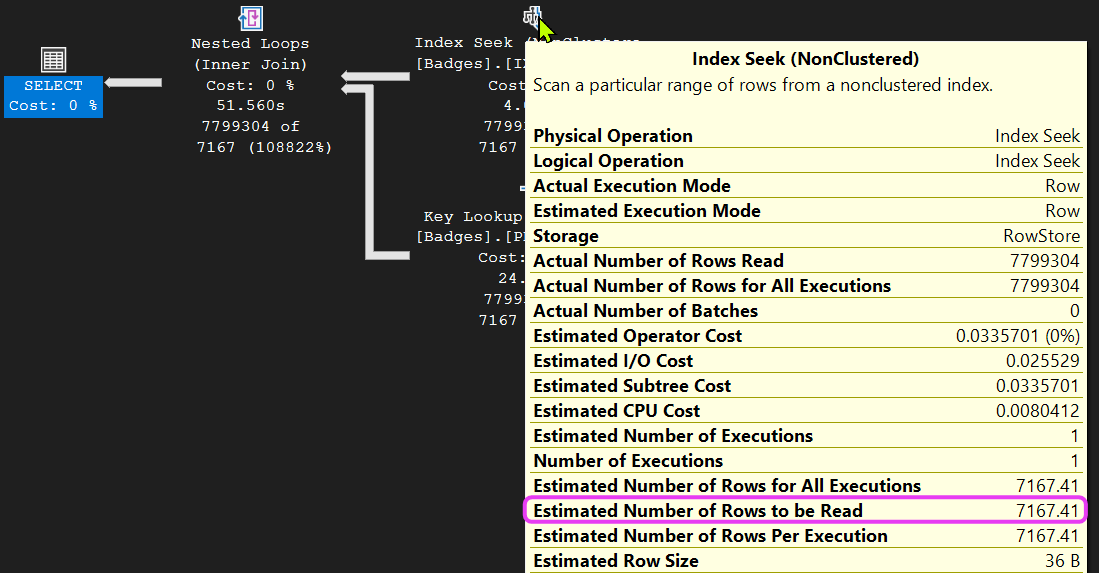
This, dear friends, sucks when considering our scenario. The last thing we would want SQL to do when using the parameter value of ‘Popular Question’ is to predict just 7,167 records are going to be encountered—because we know it’s actually 7,799,304.
NB – This behaviour is also the same behaviour seen when declaring a local variable within your procedure—a ’trick’ used back in the day to ultimately make SQL use the average value regarding the input parameter used.
Option Optimize for Value
As you would expect, the query hint OPTIMIZE FOR @value does exactly what you think. It tells SQL Server to generate a plan for a specific parameter value.
Example usage:
CREATE OR ALTER PROCEDURE dbo.Rincewind
@Badge AS NVARCHAR(40)
AS
BEGIN
SELECT
b.Name AS [BadgeName],
b.UserId AS [UserId],
b.Date AS [DateAwarded]
FROM dbo.Badges b
WHERE b.Name = @Badge OPTION (OPTIMIZE FOR (@Badge = 'Popular Question'))
END
GO
The above would instruct SQL to always create the best plan it can for the input parameter of ‘Popular Question’.
This can be a good solution ‘if’ you know your data very well and you are confident that your data is rarely changing. Hardcoding such business logic into your code is generally a bad idea. It adds technical debt to your operation and becomes yet another thing to keep tabs on and maintain over time.
With that said, however, in the right scenario it can be a good fit. For example, using our demo, we know that the plan for ‘Popular Question’ works well enough for both parameter values ‘Popular Question’ and ‘powerpoint’, and in this isolated scenario, having the ability to say “always give me the plan suited for large dataset” is actually pretty useful.
Query Store
Query Store first appeared in SQL Server 2016, and I, for one, am a huge fan of it. One of my most used features of Query Store is the ability to quickly force a particular plan. As you can imagine, this can be very useful when considering the topic at hand.
Considering the demo procedure we used in the previous post, we can see that within Query Store, we have two plans present for the procedure dbo.Rincewind:
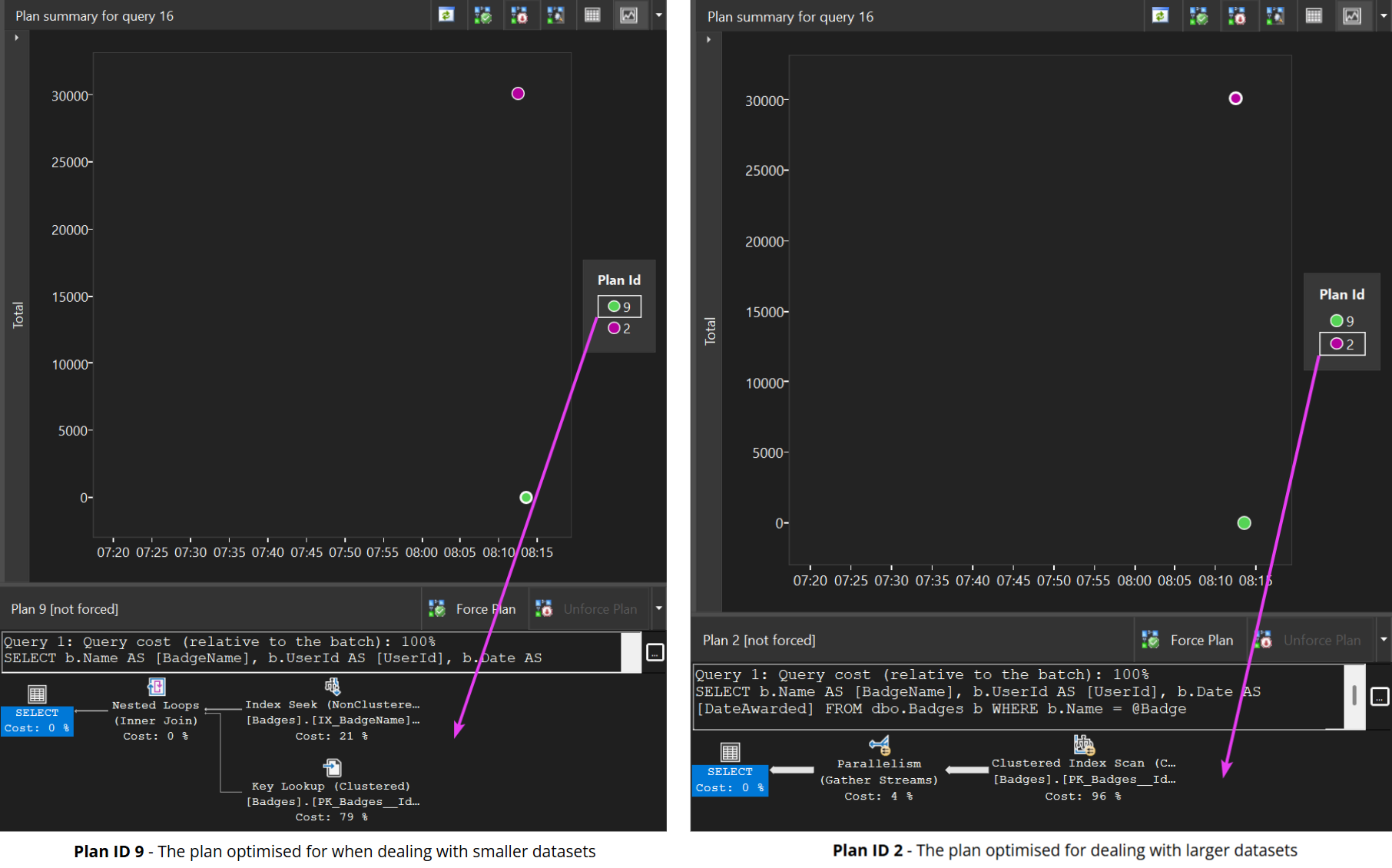
Using Query Store, we can simply choose one of these two plans and force it to be used for future executions of the procedure. I love this feature, as it’s so easy to implement and requires zero code changes.
SQL Server Version
From SQL 2022, things got better with the introduction of Parameter Sensitive Plan optimisation. This new-to-SQL 2022 feature directly combats the issue of parameter sensitivity.
Sure, there are still known aspects of it which are not ideal; however, it’s definitely a step in the right direction.
This feature allows SQL to cache multiple plans for a single parameterised statement (for example, a stored procedure). Each of those cached plans would be optimised for different-sized datasets, based on the value passed in via your parameter.
All this is possible by using the statistics histogram to identify disparity across the affected datasets.
When SQL initially compiles a stored procedure, a dispatcher plan will be created, and this dispatcher plan will map to the variations of the query. This diagram from Microsoft shows the structure of this mechanism:
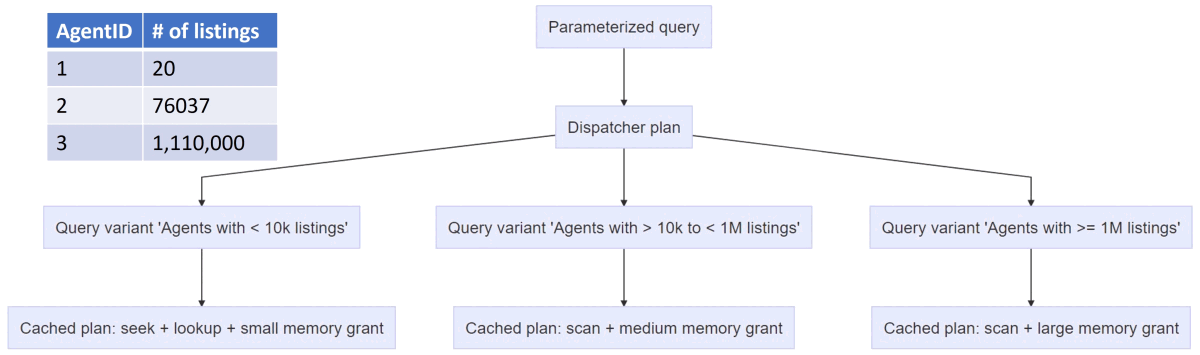
Running our own demo procedure dbo.Rincewind on a SQL 2022 instance, we see this dispatcher plan within the plan cache:
If we look at the plan XML for the dispatcher plan, we can see this line now, which details the boundaries at play:
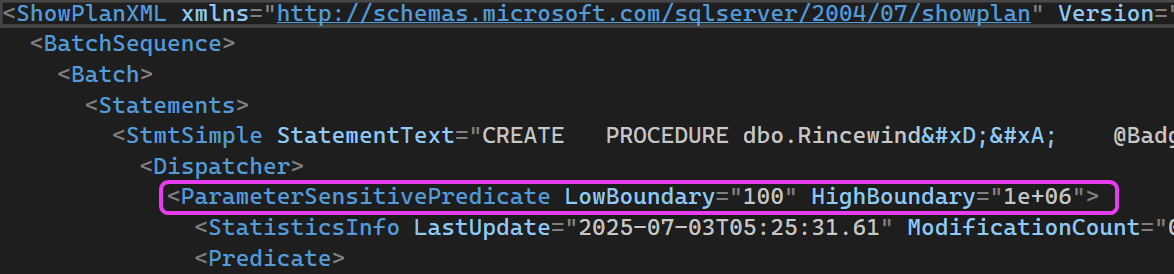
This plan will identify which plan to map to, given the input parameters passed to dbo.Rincewind - pretty cool, huh? Using this setup, my procedure will use the more optimal plan for the input parameters given. Regardless of the order I use my two input parameters, I always get the better plan.
There are some caveats, however:
- Only works with equality predicates (for example, ID = 1 and not ID > 1)
- Only identifies up to three of the most ‘at risk’ predicates. This is to avoid plan cache bloat
- Can incur additional resource utilisation due to the additional logic being used to determine plan choice
- More plans per query are now stored, which can increase plan cache size and potentially memory requirements
Closing Thoughts
In today’s post, we covered some of the options you have when facing parameter sniffing issues. There are more available and some are more successful than others. However, these are the ones I see most commonly used when working with different clients.
As with most things in SQL Server, it’s all about picking the correct tool for the job, at the correct time, and so I would urge you to fully understand the options available before implementing them. The last thing anyone wants to see is a 10,000-line pull request littered with OPTION RECOMPILE, right? 🙂
Thanks for reading!
If you’ve found this post helpful or would just like to support the work I do here, consider buying me a coffee.
